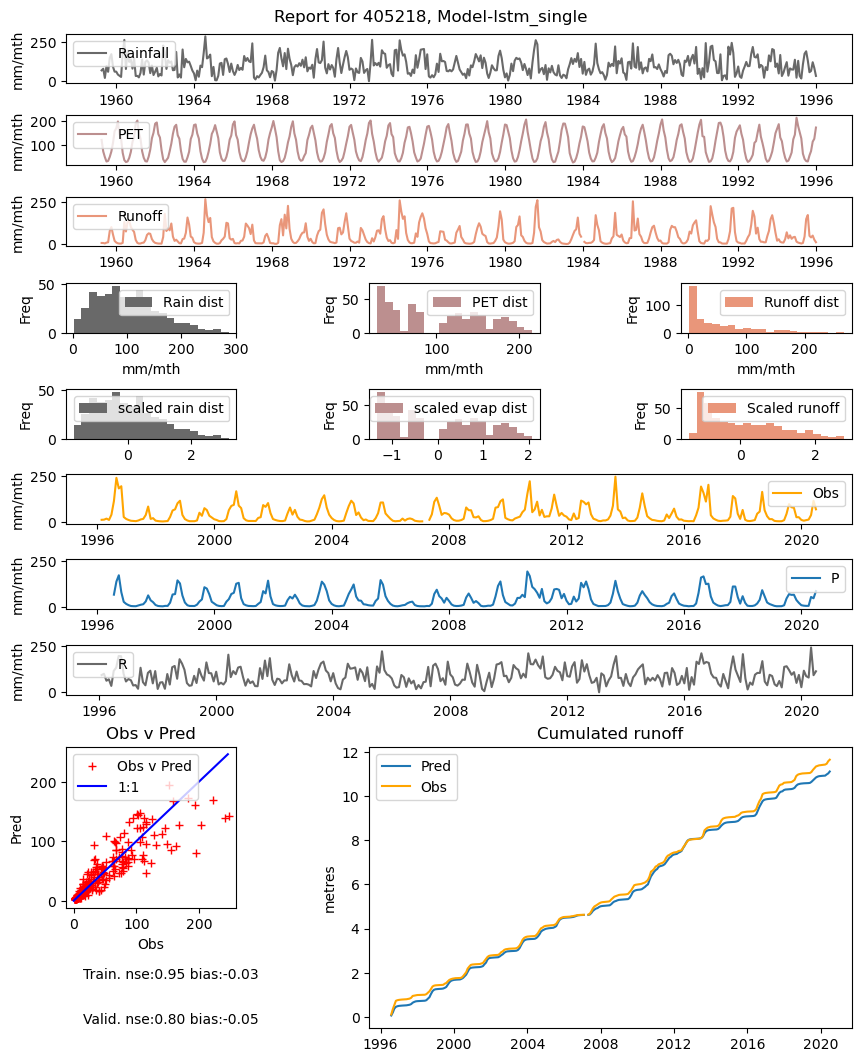
Sample workflow LSTM for lumped catchment monthly runoff
This vignette gives an introduction to using the ozrr package to define how to train an LTSM model for the simulation of monthly runoff.
It uses an arbitrary catchment and training hyperparameters, for illustrative purposes.
Imports and logistics
import pandas as pdimport numpy as npfrom pathlib import Pathimport tensorflow as tfimport os
2023-05-04 10:33:11.642840: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
from ozrr_data.repository import load_aus_rr_datafrom ozrr.tfmodels import CatchmentTraining, checked_mkdir, mk_model_filename
# TODO later: use tensorboard# %load_ext tensorboard
Usually, deep learning training is much faster on GPUs, which can be tricky to get to work.
However, in our particular use case (single catchment) training runs faster on a laptop CPU than a fairly decent GPU, about three times faster, as the parallelism offered by GPUs does not offer advantages. So, we will force the device to be a CPU, anyway.
tf.config.list_physical_devices('GPU')
[]
tf.config.set_visible_devices([], "GPU") # force CPU execution
The input dataset used in this paper takes the form of multiple comma separated value files. However this section “hides” this detail by using some helper classes and functions to load these into an xarrayDataArray.
OzrrPathFinder is not key to this vignette and you can ignore it.
from ozrr._boilerplate import OzrrPathFinderpf = OzrrPathFinder()root_dir_f = pf.find_input_data_dir()
On the first call to load_aus_rr it may take around 3 minutes to ingest the hundreds CSV files, if from a local file system.
However once done, the directory has a netcdf cached entry, and subsequent loading will only take a few seconds, and a fraction of a second with lazy loading.
The ozrr package includes provision to make sure outcomes are deterministic (broadly speaking by using seeds as argument to tensorflow functions). However, some states in Tensorflow seem to be global, so we also need a static call to tf.random.set_seed.
## GLOBAL SEED ##tf.random.set_seed(123456)TRAINING_SEED =42
Config and Hyperparameters
station_id ="405218"
CatchmentTraining is a high level class that deals with setting up the model and data to use for the fitting, hiding the tedium.
eval_end_date is an approximation given the end date of the input climate data set for most, but not all catchments.
The data handling module in ozrr deals with trailing missing values to find the correct last full month of data prior to that for aggregation, e.g. 2020-06-30, or 2020-05-31.
ct.conf.stateful =Falsect.fit_verbosity =0# https://www.tensorflow.org/api_docs/python/tf/keras/Modelct.eval_verbosity =0# https://www.tensorflow.org/api_docs/python/tf/keras/Model# Force a reload of the data; we may have changed the time span specifications.# will be refactored later# ct.reload_data()from ozrr.tfmodels import lstm_single
2023-01-30: trying to reproduce some unexpectly disappointing results on a round of batch calibrations.
ct.conf.n_epochs=100ct.conf.train_start_date=pd.Timestamp("1950-01-01")ct.conf.train_end_date=pd.Timestamp("1995-12-31")ct.conf.eval_start_date=pd.Timestamp("1996-01-01")ct.conf.eval_end_date=pd.Timestamp("2020-07-15")ct.conf.batch_size=24ct.conf.seq_length=6ct.conf.num_features=3ct.conf.feature_ids=["rain", "pet", "eff_rain"]ct.conf.steps_per_epoch=100ct.conf.shuffle=Truect.conf.stride=1ct.conf.lstm_dim=10ct.conf.logging="false"# false (default), tensorboard, wandbct.conf.log_dir="ignored"# directory for log outputct.conf.use_validation=False# Should there be a training/validation split of the calibration period as a strategy to prevent model overfitting. ct.conf.early_stopping=Falsect.conf.early_stopping_patience=14ct.conf.lr_patience=3ct.conf.lr_factor=0.5ct.conf.lr_start=0.05ct.conf.dropout=0.1ct.conf.recurrent_dropout=0.1
model_func needs to be reset AFTER the settings above. This will trigger the creation of the model with newer parameters. This is a design compromise resulting from legacy.
ct.conf.model_func ="lstm_single"
# ds = data_repo.data_for_station(station_id)
A data object holds the observations aggregated to monthly, and their scaled version
x = ct.scaled_training_data()
x.x
rain
pet
eff_rain
t
1959-03-31
-0.532426
0.385026
-0.694146
1959-04-30
-0.353701
-0.483118
-0.176882
1959-05-31
-1.363860
-0.914580
-1.096170
1959-06-30
-0.063804
-1.247830
0.144238
1959-07-31
-0.692425
-1.207809
-0.478399
...
...
...
...
1995-08-31
-0.734161
-0.792916
-0.617635
1995-09-30
-0.598107
-0.459398
-0.619684
1995-10-31
0.358981
0.254840
0.339624
1995-11-30
-0.270291
0.471712
-0.604118
1995-12-31
-1.142052
1.325237
-1.035516
442 rows × 3 columns
if model_file.exists(): model_file.unlink()
import tensorflow as tfimport logging# Set the verbosity level to 'WARNING' or 'ERROR' to suppress the outputtf.get_logger().setLevel(logging.WARNING)
%%time result = ct.train(random_seed=TRAINING_SEED)
2023-05-04 10:36:29.324729: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
CPU times: user 45.5 s, sys: 2.89 s, total: 48.4 s
Wall time: 21 s